
Joshua had been waiting anxiously for weeks. As an aspiring clerk, he knew that the government official’s appointment order could arrive any day. This appointment was crucial—it would determine his future and career. Every morning, Joshua checked his local post office, hoping that today would be the day the letter arrived, confirming his new position.
In many ways, Joshua’s experience mirrors how Kafka, a powerful distributed streaming platform, manages and delivers data. Just like how Joshua relies on the postal system to receive his appointment letter, modern data systems depend on Kafka to ensure that critical information reaches its intended recipients quickly and reliably.
In this post, we’ll explore how Kafka functions as the backbone of modern data streaming, using Joshua’s story and the analogy of a postal service to make these concepts easy to understand.
Kafka Architecture
Kafka’s architecture is designed for high throughput, low latency, and fault tolerance, much like a well-organized postal system that ensures messages are delivered efficiently and accurately. Here’s a breakdown of how Kafka’s architecture supports these goals:
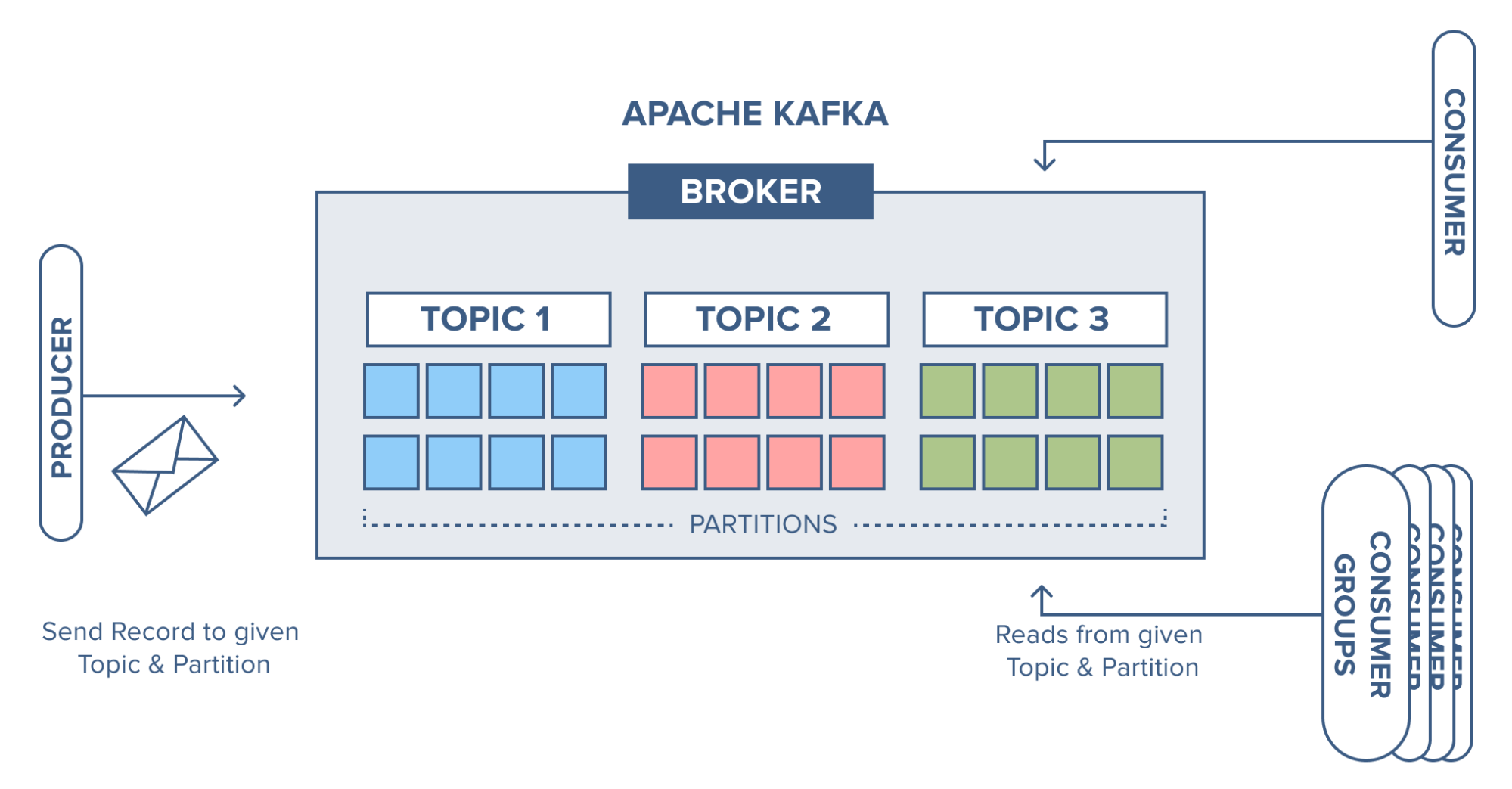
Brokers as Post Offices: Kafka brokers handle the heavy lifting of managing the data flow between producers and consumers. Each broker in a Kafka cluster is like a post office, managing and storing messages, and ensuring they are delivered to the correct topic (county) and partition (district).
Topics as Counties and Partitions as Districts: Data in Kafka is categorized into topics, which are further divided into partitions. This division allows Kafka to scale horizontally, distributing the load across multiple brokers, much like how letters are sorted and delivered across different districts within a county.
Producers and Consumers: Producers send messages to specific topics, deciding which partition to use based on a key or other logic. Consumers then retrieve these messages from the partitions they are assigned to, ensuring that each message is processed in the correct order.
KRaft (Kafka Raft): Kafka has evolved from using Zookeeper to manage metadata and leader elections to using KRaft, an integrated consensus algorithm based on Raft. KRaft simplifies Kafka’s architecture, making it more efficient and scalable, akin to upgrading from a manual postal system to an automated one.
Kafka Connect and Kafka Streams
As Kafka grew in popularity, additional tools were developed to extend its functionality, making it even more powerful for real-time data processing.
Kafka Connect: Kafka Connect is a framework for connecting Kafka with external systems such as databases, key-value stores, search indexes, and file systems. Think of Kafka Connect as an intermediary that helps Kafka integrate with other systems, much like a post office that not only delivers letters but also handles packages, money orders, and other services. It allows you to easily move large amounts of data in and out of Kafka without writing complex code.
Kafka Streams: Kafka Streams is a powerful library for building real-time applications that process data in Kafka. It allows you to perform complex transformations, aggregations, and joins on the data as it flows through Kafka. Imagine Kafka Streams as an automated sorting system within the post office that not only delivers the mail but also opens it, reads it, and takes action based on its contents. With Kafka Streams, you can build applications that react to data in real time, providing immediate insights and responses.
Real-World Applications
Kafka’s role in data streaming is akin to the postal service’s role in communication. Whether it’s real-time analytics, event sourcing, or data integration, Kafka ensures that data reaches its intended recipients efficiently and reliably.
Kafka’s architecture, combined with tools like Kafka Connect and Kafka Streams, makes it a powerful platform for handling a wide range of data processing tasks. From integrating different data systems to building real-time processing pipelines, Kafka is the backbone of many modern data infrastructures.
Conclusion
Just as Joshua relies on a well-organized postal system to receive his appointment letter, modern data systems depend on Kafka to ensure that critical information is delivered accurately and efficiently. By understanding Kafka through this postal service analogy, we can appreciate how it organizes, processes, and delivers data across distributed systems.
Whether you’re a developer, architect, or simply curious about how modern data systems work, Kafka’s ability to deliver data reliably and efficiently is worth exploring. Ready to dive deeper? Check out our other posts or Kafka’s official documentation to learn more.
Ready to dive deeper into Kafka? Start by setting up your own Kafka and Kafka Connect with our installation guide, and begin exploring the endless possibilities of real-time data processing.